Address
Pittsburgh, PA
Work Hours
Monday to Thursday: 9AM - 5PM ET
Friday: 9AM -1PM
Address
Pittsburgh, PA
Work Hours
Monday to Thursday: 9AM - 5PM ET
Friday: 9AM -1PM

Most AI tools generate answers.
AI agents evaluate outcomes.
This project started as a simple experiment: if we are running AI hackathons, why not let AI help evaluate the demos?
But the experiment quickly became something more. It turned into a hands-on exploration of what agentic AI actually means and how AI agents differ from traditional chatbots.
The result was Idea Inspector, a structured evaluation system that listens to demos, extracts signal, scores against a rubric, and generates consistent feedback. It is not a general-purpose assistant. It has a defined role, clear constraints, and repeatable behavior.
That distinction matters.
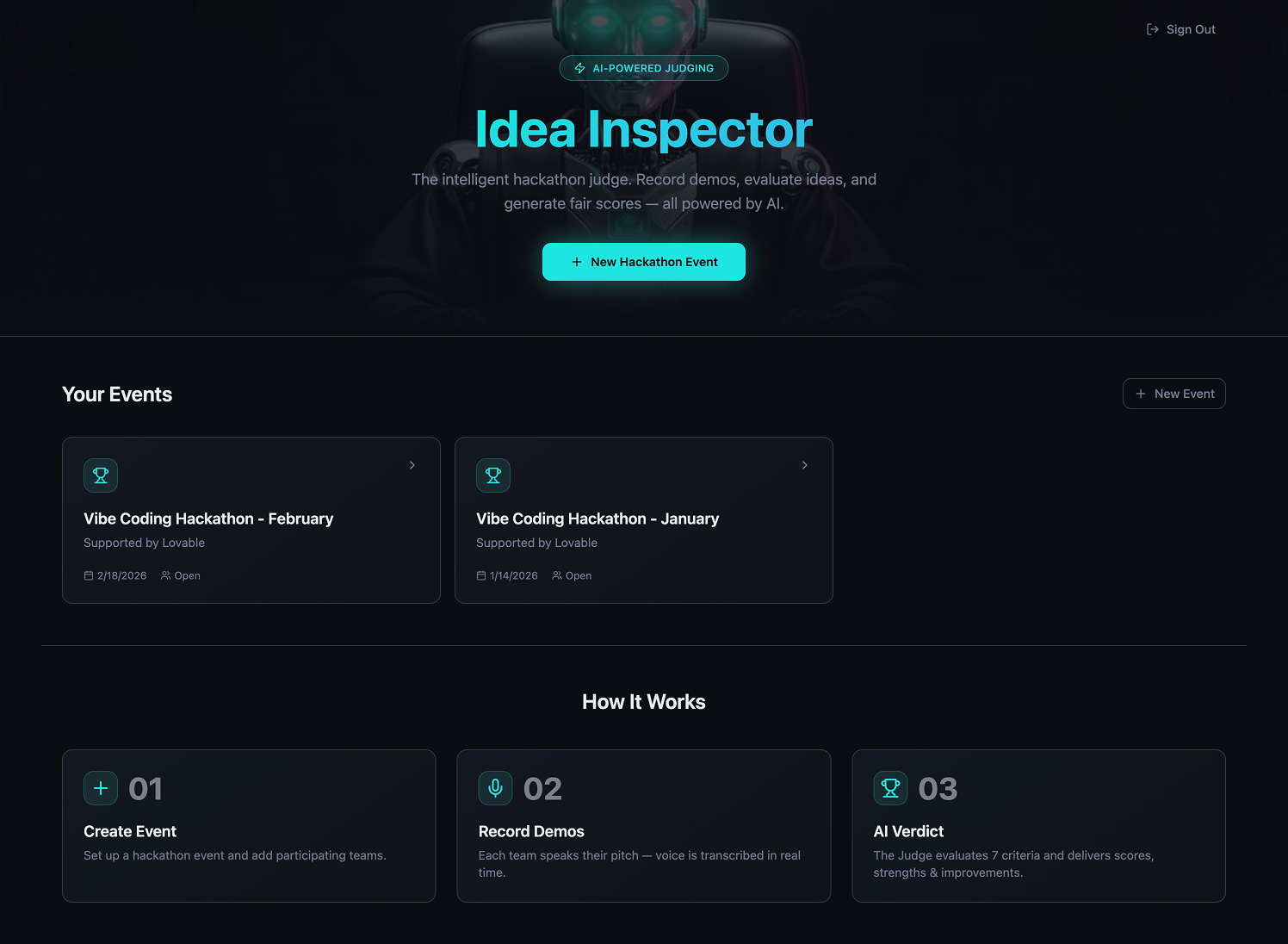
The phrase agentic AI is often used loosely. In practice, many so-called agents are still reactive chat systems. They wait for a prompt, generate text, and stop.
An AI agent operates differently. It performs a role inside a system. It follows rules. It produces structured outputs that are consistent across runs. It can be invoked repeatedly and still behave predictably.
Instead of asking a model, “What do you think of this project?” I defined a role:
That identity shapes everything. When AI has a job rather than a vague instruction, its outputs become sharper and more reliable.
Once I understood that agents evaluate outcomes rather than simply generating answers, the next question became obvious: how should an agent decide what is good?
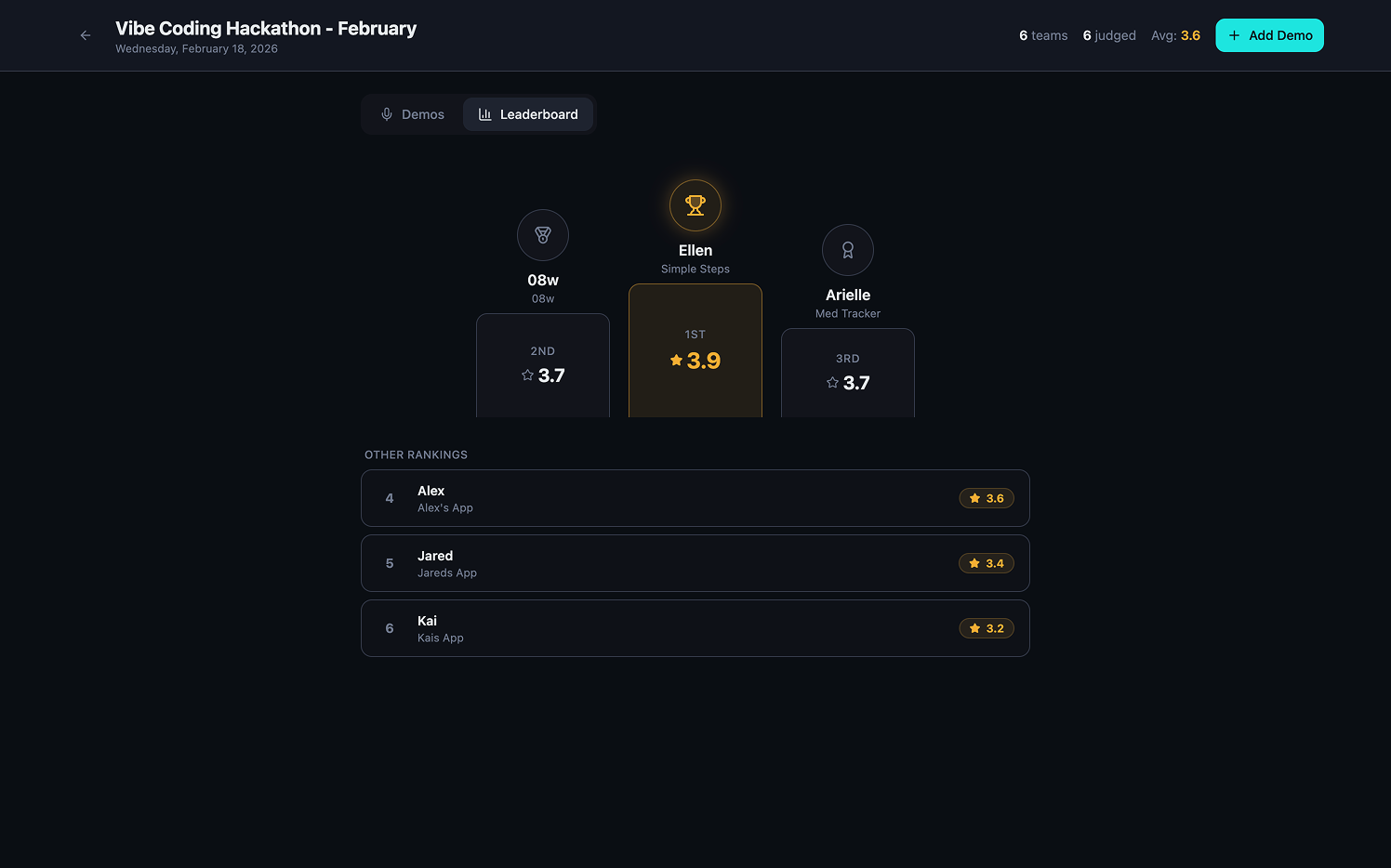
The real breakthrough in this build was the rubric. Rather than generating freeform commentary, the Idea Inspector evaluates every submission across eight criteria:
Each criterion receives a score and feedback is split into two main categories; strengths and improvements.
This structure dramatically improves quality.
When you give AI a defined evaluation framework, hallucination decreases and coherence increases. The model is not improvising in open space. It is mapping inputs to explicit categories. Constraints act as guardrails that improve clarity rather than limiting creativity.
Many teams assume more flexibility makes AI better. In my experience, the opposite is true. The tighter the frame, the stronger the signal.
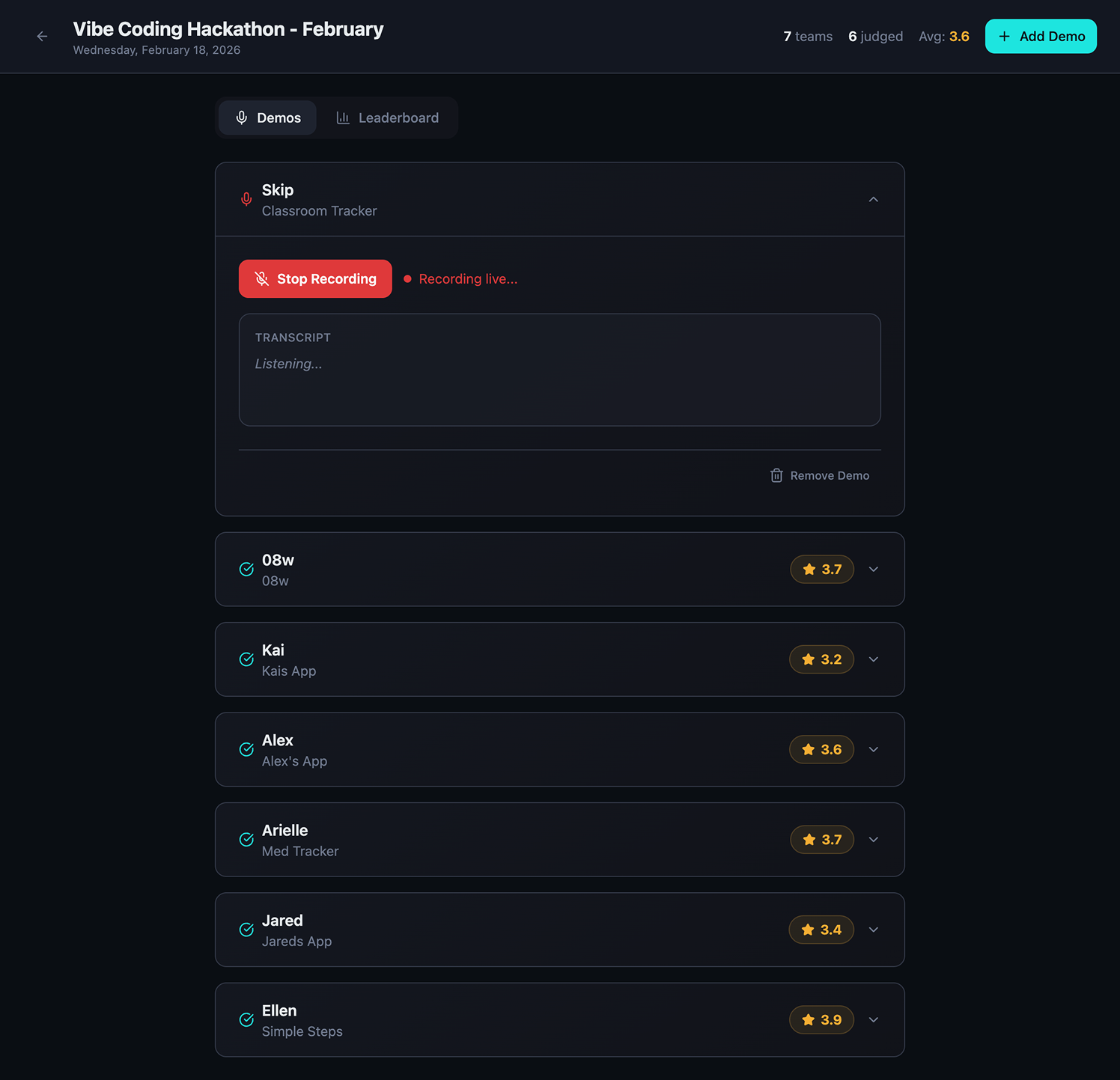
From a technical perspective, this system is layered rather than magical. The architecture looks like this:

The most important component is not the large language model itself. It is the system design around it.
For example, the scoring logic requires evidence from the demo. Feedback cannot introduce assumptions that were never stated. The ethics section must identify risks or blind spots. These constraints prevent drift and increase trust.
If you are exploring how to build an AI agent, this is the key lesson: the model generates language, but the system defines behavior.
Why This Matters
Most AI products today focus on generation.
The real opportunity is building systems that evaluate, rank, and decide.Agents shift AI from being a conversational interface to becoming an operational layer for decision making.
The difference between AI agents and chatbots becomes clear in application.
If you ask a generic chatbot to judge a demo, you may get a decent answer. But it will vary in structure, tone, and focus. It might ignore ethics. It might reward hype over substance. It might drift into unrelated commentary.
The Idea Inspector behaves consistently. It evaluates every demo across the same criteria. It produces predictable formatting. It explains its reasoning. It does not wander.
Consistency builds credibility.
One of the most interesting outcomes of this experiment was how participants responded. They did not resist AI judging their work. They leaned into it. They engaged with the feedback. Additionally, Madi and I compared scores and validated the specific criteria through two human lenses. I think this combination is powerful.
The system wasn’t perfect, but it was structured and transparent.
Trust does not require perfection. It requires predictability.
We are currently flooded with AI-generated content. Text, images, code, video. Infinite output.
What we lack is structured evaluation.
The internet does not need more content as much as it needs better filtering, scoring, and prioritization. This is where rubric-based AI systems become powerful. An AI evaluation agent can screen portfolios, review product requirement documents, score grant applications, evaluate design systems, or triage bug reports. It can serve as a first-pass filter, surfacing signal for human decision-makers.
This is not about replacing people. It is about augmenting tasks at scale.
This project reinforced something I have been exploring across multiple builds. The most effective AI systems are not trying to do everything. They are trying to do one thing clearly.
The Mac Miller app worked because it had a defined tone and worldview. It operated within a boundary. That boundary created coherence.
The Idea Inspector follows the same philosophy. It is not a productivity assistant or a brainstorming partner. It is a judge. Its scope is narrow and intentional. That clarity reduces confusion and increases reliability.
In a world of increasingly general AI tools, specificity becomes a strength. Define the role. Define the rules. Let the agent operate.
If you are building agentic AI systems, here are the core lessons from this field experiment:
Most teams focus heavily on model selection. The greater leverage lies in workflow design.
This prototype is small, but it hints at a broader future.
Imagine multi-agent evaluation systems where a Technical Agent scores design portfolios, a UX Agent evaluates usability and accessibility, and an Ethics Agent assesses bias and risk. Each agent operates against a defined rubric. Each produces structured output. Humans synthesize the results and make the final call.
That begins to look like an AI operating layer for evaluation.
If the first wave of AI focused on generation, the next wave will focus on judgment, orchestration, and structured decision-making. Agentic systems are not about giving models more freedom. They are about giving them better constraints.
Building this system clarified something for me.
The future of AI in product design and innovation is not about better prompts in chat windows. It is about designing systems where AI behaves with purpose.
Define the role.
Define the rubric/framework.
Let the agent do its job.
Then build the next one.
If you’re experimenting with agentic systems or building your first AI agent, I’d love to hear what you’re working on.